llama.cpp 推理教程
llama.cpp 是一个轻量化的大语言模型运行框架,专门优化了在 CPU 上运行模型的性能。
随着 RWKV 社区成员 @MollySophia 的工作,llama.cpp 现已适配 RWKV-6/7 模型。
本章节介绍如何在 llama.cpp 中使用 RWKV 模型进行推理。
视频教程
高画质视频请跳转到 B 站观看。
llama.cpp 推理 RWKV 模型
本地构建 llama.cpp
可以选择从 llama.cpp 的 release 页面下载已编译的 llama.cpp 程序。
llama.cpp 提供了多种预编译版本,根据你的显卡类型选择合适的版本:
| 系统类型 | GPU 类型 | 包名称字段 |
|---|---|---|
| macOS | 苹果芯片 | macos-arm64.zip |
| Windows | 英特尔 GPU(含 Arc 独显/Xe 核显) | win-sycl-x64.zip |
| Windows | 英伟达 GPU(CUDA 11.7-12.3) | win-cuda-cu11.7-x64.zip |
| Windows | 英伟达 GPU(CUDA 12.4+) | win-cuda-cu12.4-x64.zip |
| Windows | AMD 和其他 GPU(含 AMD 核显) | win-vulkan-x64.zip |
| Windows | 无 GPU | win-openblas-x64.zip |
也可以参照 llama.cpp 官方构建文档,选择适合的方法本地编译构建。
获取 gguf 格式模型
llama.cpp 支持 .gguf 格式的模型,但 RWKV 官方仅发布了 .pth 格式模型。因此,我们需要使用以下两种方法之一获取 .gguf 格式的 RWKV 模型。
可以从 RWKV-GGUF 合集 下载 gguf 格式的 RWKV 模型。
请在 llama.cpp 目录下新建一个 models 文件夹,将下载的 gguf 模型放入 models 文件夹中。
RWKV gguf 模型有多种量化类型,精度越高,模型的回复效果越好,但模型体积和计算要求越高。
推荐顺序:FP16 > Q8_0 > Q5_K_M > Q4_K_M ,更低的量化精度(如 Q3_0、Q2_0 等)可能会大大降低模型的性能。
- 首先,从 Hugging Face 或魔搭平台(国内可访问)下载一个
pth格式的 RWKV 模型 - 从 MollySophia/rwkv-mobile 仓库 下载
convert_hf_to_gguf.py转换脚本 - 下载 RWKV 分词表rwkv_vocab_v20230424.txt,确保分词器和转换脚本放在同一目录下
- 运行
pip install torch gguf命令,安装转换脚本所需的依赖项 - 在转换脚本目录下运行以下命令,将
pth格式的模型转换为gguf格式的模型
python convert_rwkv_pth_to_gguf.py [pth模型文件路径] rwkv_vocab_v20230424.txt请将上述命令中的 [pth模型文件路径]改成你的 pth 格式 RWKV 模型路径。
运行 RWKV 模型进行对话
在 llama.cpp 目录运行以下命令,可以开启 llama.cpp 的命令行对话模式:
./llama-cli -m models/rwkv-6-world-7b-Q8_0.gguf -p "You are a helpful assistant" -cnv -t 8 -ngl 99 -r "\n\n"这条命令通过 llama-cli 运行 models/rwkv-6-world-7b-Q8_0.gguf 模型,使用 8 个线程、并根据给定的初始 prompt You are a helpful assistant 开启对话。
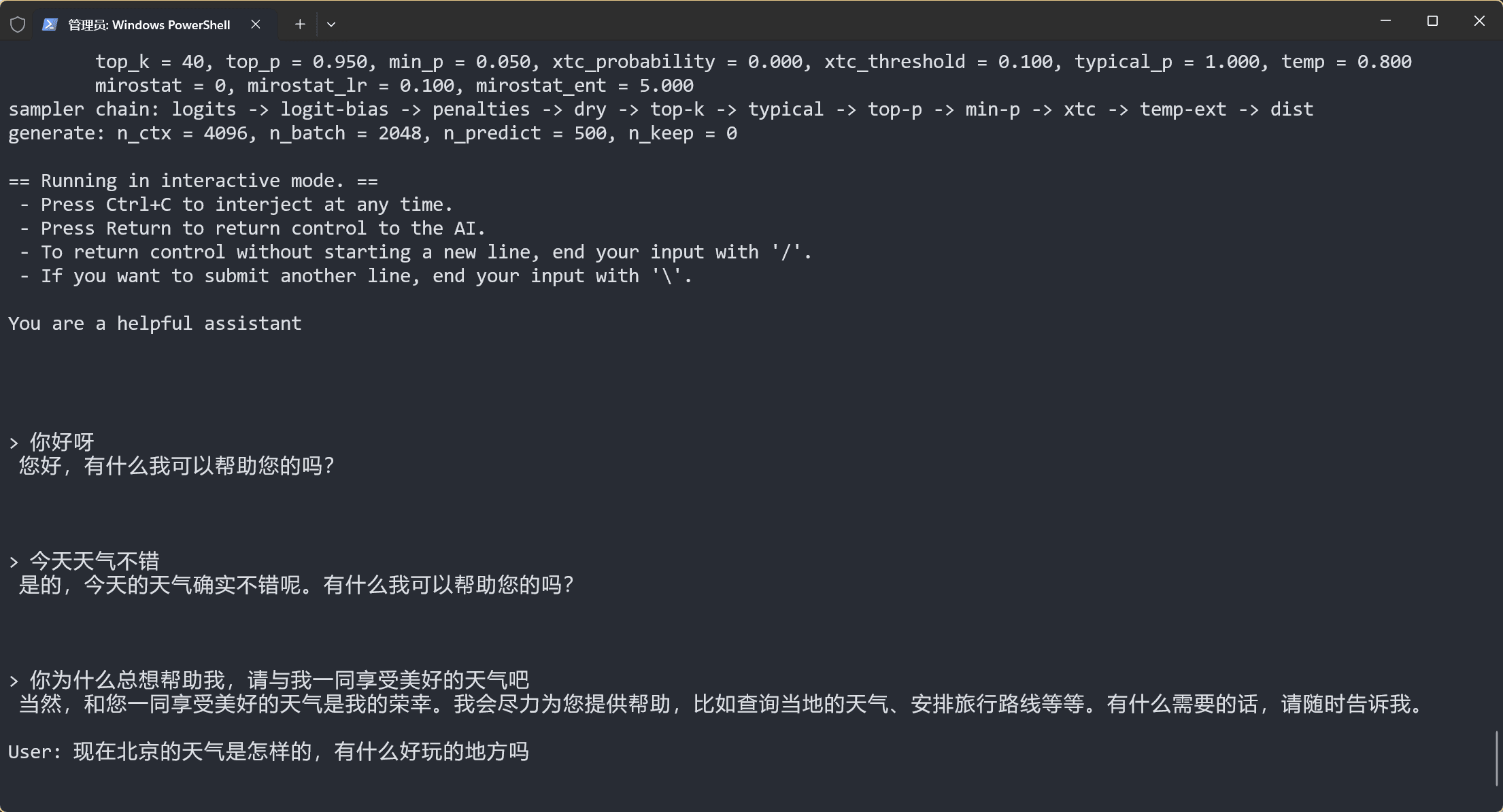
参数解释:
./llama-cli:启动编译好的 llama-cli 程序-m models/rwkv-6-world-7b-Q8_0.gguf:模型的路径参数-p "You are a helpful assistant":初始 prompt 参数,模型根据该提示词开启对话-cnv:开启对话模式,此参数为默认参数,可以省略-t 8:指定线程数,建议根据可用的物理 CPU 核心数调整,可以省略(省略则默认为物理核心数)-ngl:指定使用 GPU 加载的模型层数,可以通过设定-ngl 99,使用 GPU 加载 RWKV 模型所有层-r:用于以字符串形式匹配的停止词,rwkv模型需要指定为"\n\n"(双换行)
完整的参数列表可以在 llama.cpp 参数文档中查看。
附加功能(可选)
启用续写模式
./llama-cli 默认是对话模式。可通过添加 -no-cnv 参数设置为续写模式,根据给定的 prompt 继续生成文本。
./llama-cli -m models/rwkv-6-world-7b-Q8_0.gguf -p "User: What's mbti?tell me in chinese.\n\nAssistant:" -no-cnv -t 8 -ngl 99 -n 500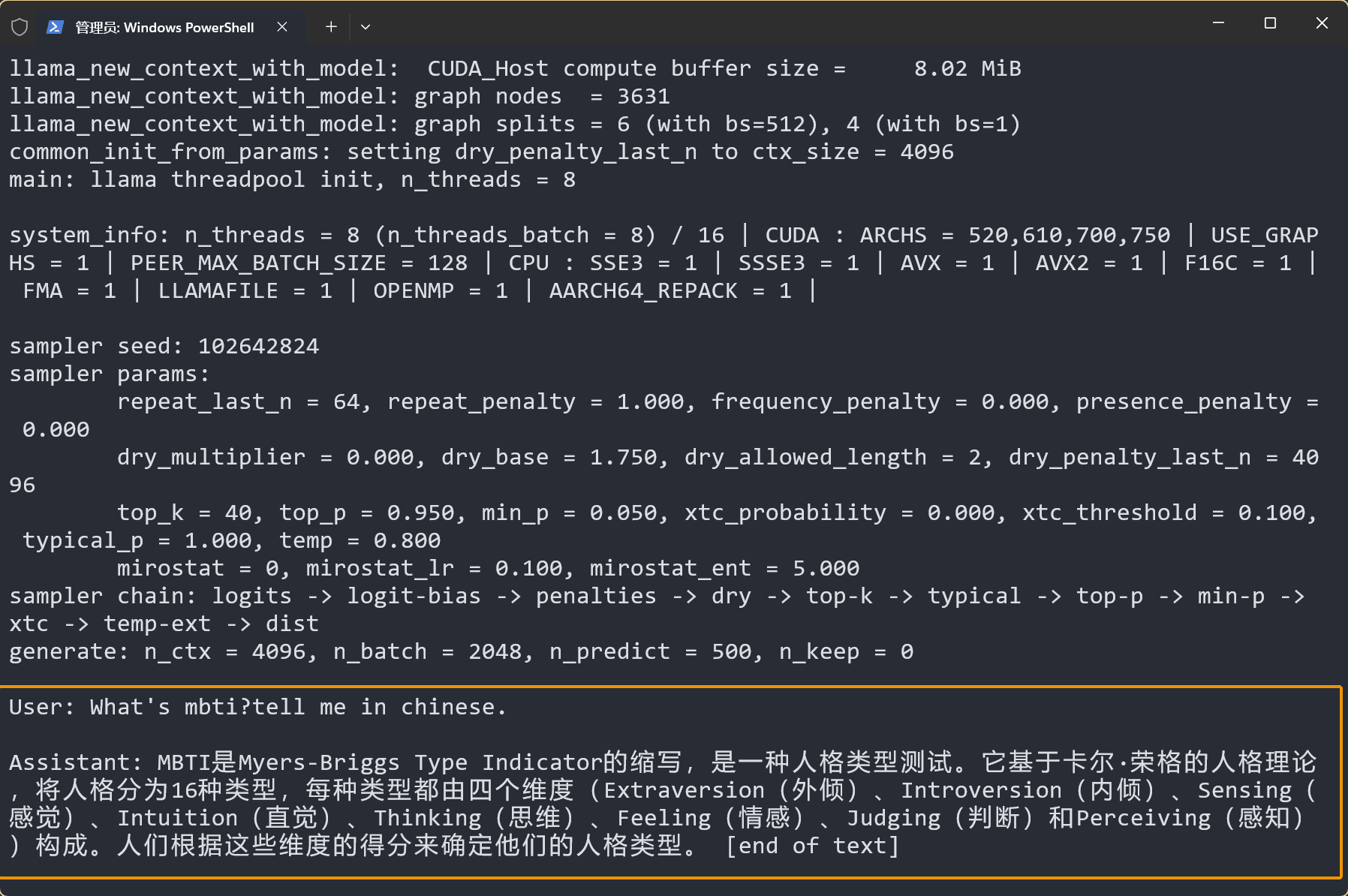
-p "User: What's mbti?tell me in chinese.\n\nAssistant:": prompt 参数,模型根据该提示词进行续写。更多 RWKV prompt 格式请在 RWKV 的提示词格式中查看-no-cnv参数:关闭对话模式,设置 llama.cpp 为续写模式,模型会根据给定的 prompt 继续生成文本- 其他参数:与对话模式相同
启动 Web 服务(推荐)
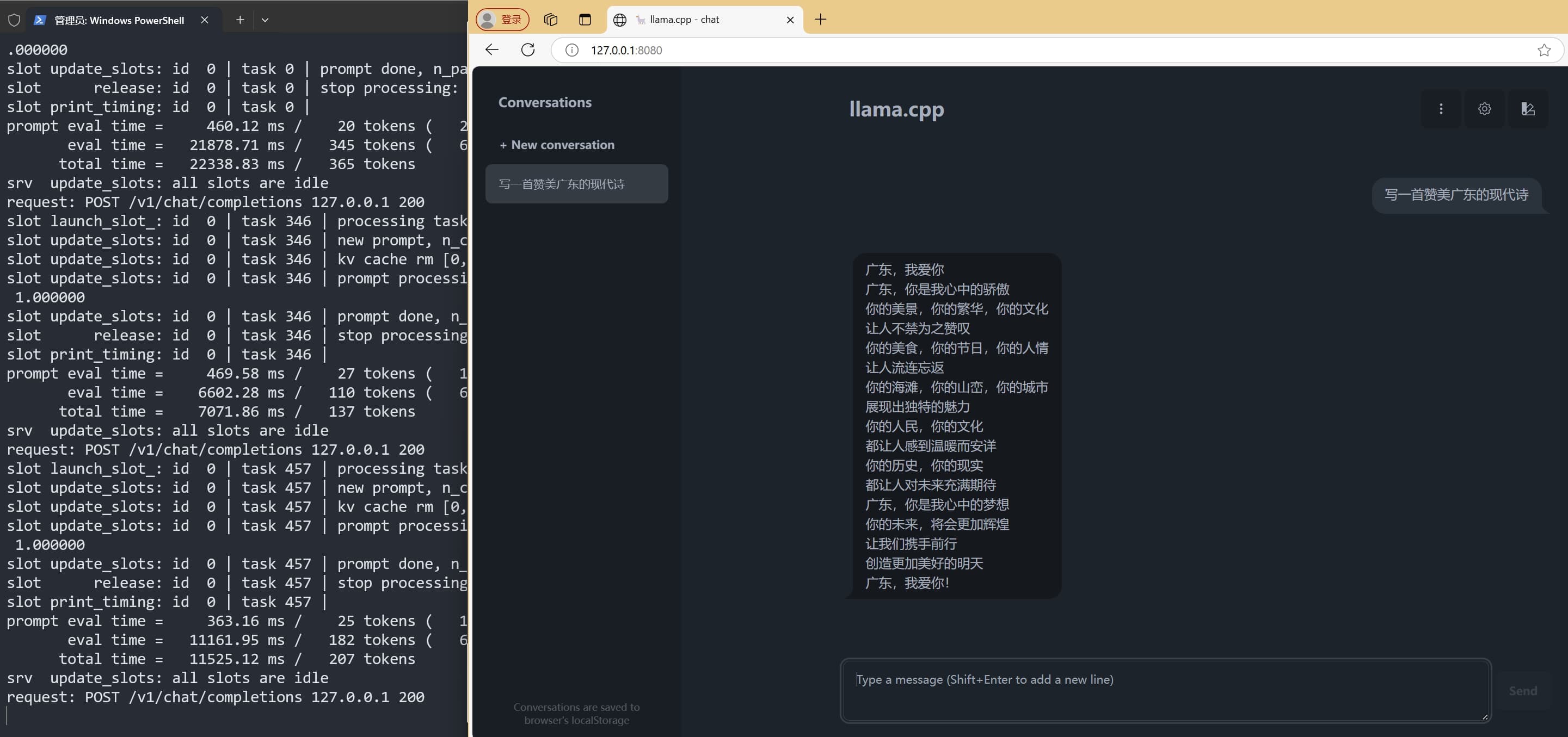
使用以下命令,启动 llama.cpp 的 Web 服务:
./llama-server -m models/rwkv-6-world-7b-Q8_0.gguf -ngl 99 -r "\n\n"启动后,可以通过 http://127.0.0.1:8080 访问 llama.cpp Web 页面:
量化 gguf 模型
在 llama.cpp 目录运行 ./llama-quantize [input_model] [output_model] [quantization_type] 命令,可以对 fp32 和 fp16 的 .gguf 模型进行量化,例如:
./llama-quantize models/rwkv-6-world-1.6b-F16.gguf models/rwkv-6-world-1b6-Q8_0.gguf Q8_0输入模型的精度限制为 fp32 和 fp16,推荐使用 Q5_1、 Q8_0 两种量化精度。
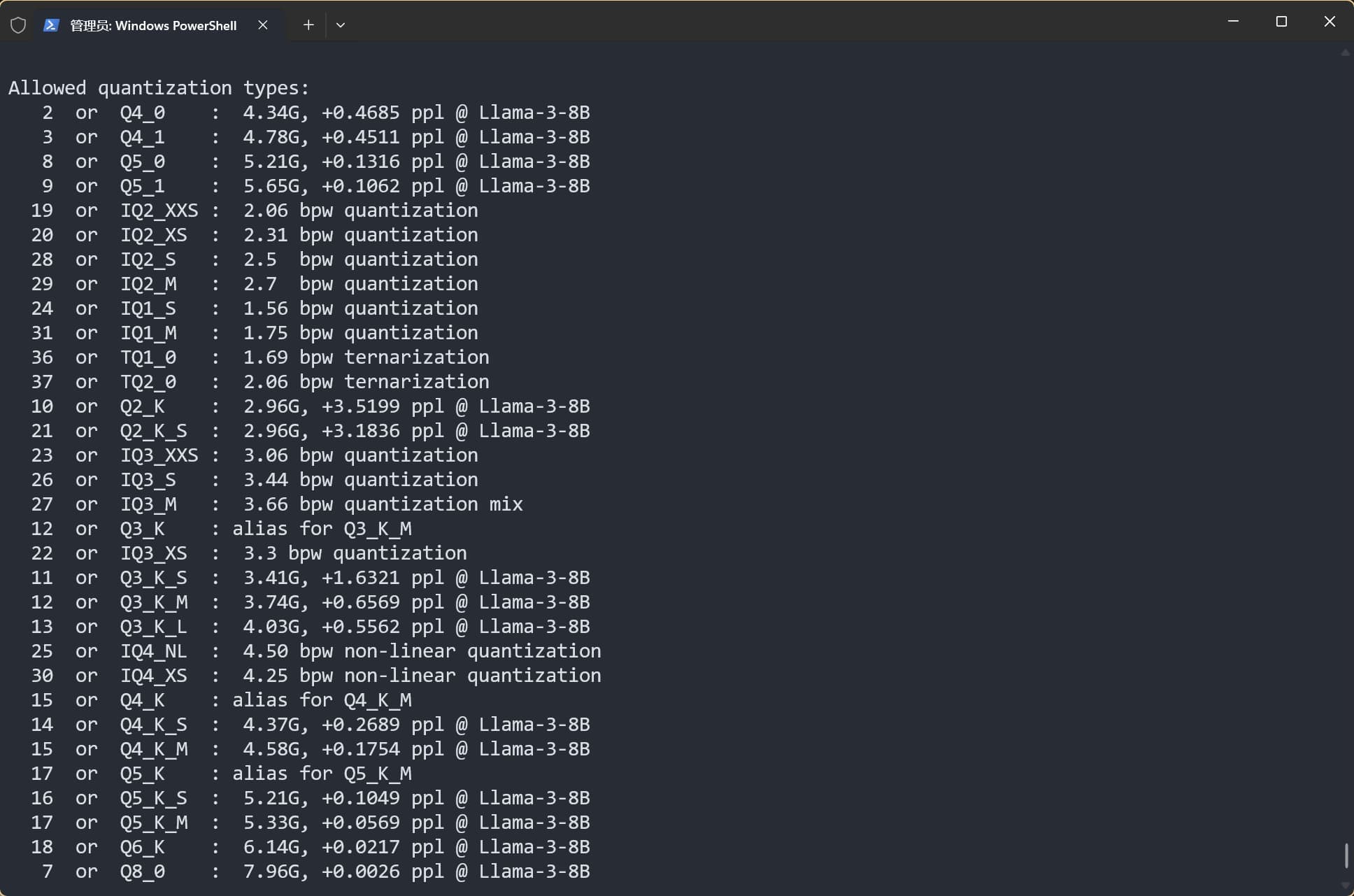
使用 ./llama-quantize --help 命令,查看所有可选的量化精度: